
Partitioning is one of the most powerful and sometime misunderstood concept in Apache Kafka. It defines how data is distributed, processed and ordered in a system. In this post I will try to explain why it matters, how it works and when to use it.
What is a Partition?
A Kafka Topic is split into partitions. Each partition is an ordered and immutable log. Records inside a partition are strictly ordered. Different partitions can be stored on different brokers (horizontal scaling).
ChatGPT helped me find a nice explanation: Think of partitions as lanes on a highway. Cars in the same lane follow a strict order, but cars in different lanes may arrive in a different sequence.
How partitioning works?
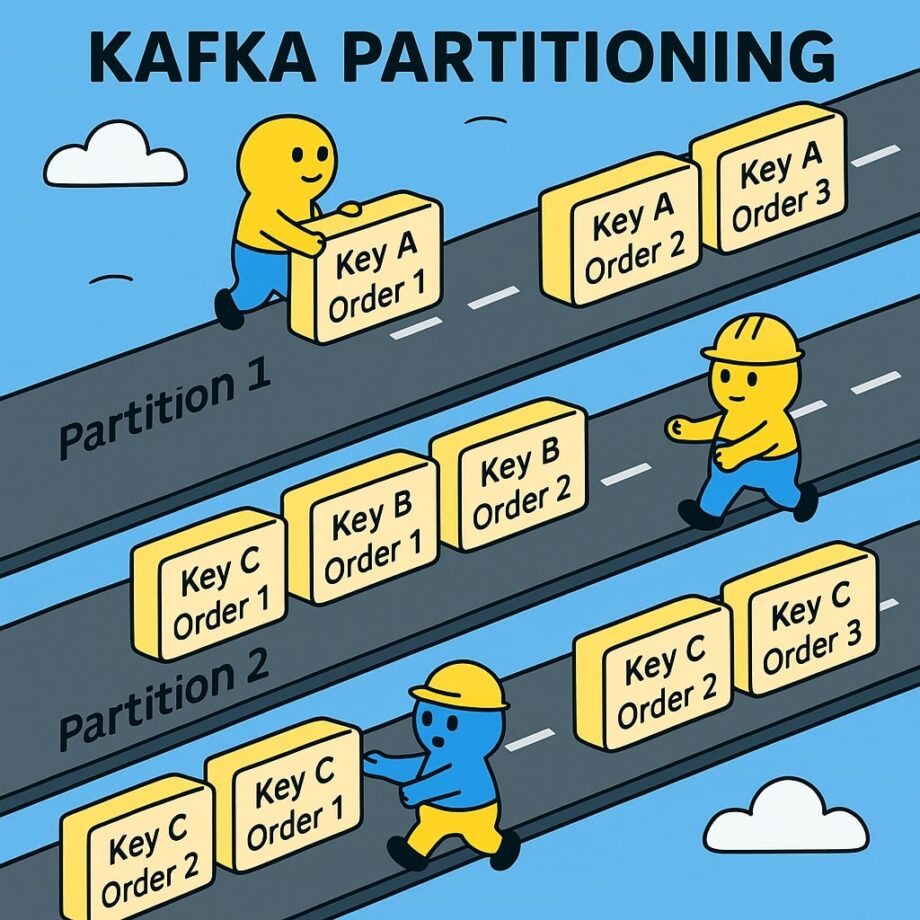
When a producer sends a record, Kafka needs to decide which partition it goes to. Following strategies are available:
- Key-based routing. If you send key (e.g., customerId), Kafka ensures all records with the same land in the same partition
- Round-robin. If no key is provided, records are spread evenly across partitions.
- Custom partitioner. You can plug in the own strategy.
Why partitioning matters?
Ensuring Data Ordering
Let’s say we have an e-commerce order system. All specific order (by orderId) must be processes in a sequence: OrderCreated -> PaymentProcessed -> OrderShipped. Using orderId as the partition key guarantees ordering within that partition.
Scaling Consumer Throughput
Use case: log processing pipeline
- Millions of application logs are pushed into Kafka every minute
- You want multiple consumers to precess them in parallel
- Solution: Increase the number of partitions so that more consumers can subscribe. Each of them read a subset of partitions independently
Balancing Load Across Consumers
Use case: IoT device data ingestion
- millions of sensors send temperature readings
- you don’t care about ordering between devices, but you need balanced load
- Solution: Use deviceId as the key to keep one device’s events together or no key at all if ordering isn’t important. Kafka will spread the load evenly.
Isolating Critical Systems
Use case: Fraud detection in banking
- Transactions for the same account must be processes in order to detect anomalies.
- Solution: Partition by accountId ensures ordered processing while scaling across accounts.
Rebalancing
Rebalancing happens when partitions or consumers change – for example, a new consumer joins, one crashes or partitions are added. Kafka then redistributes partitions so load stays balanced.
Consumer groups: Traditionally, all consumers paused during rebalances (“eager” protocol). Modern cooperative rebalancing protocol (which is recommended now) moves only what’s necessary, keeping most consumers working and reducing downtime.
Broker/leader side: Kafka also rebalances partition leaders across brokers to avoid hotspots, either automatically or via admin tools.
With KRaft (Kafka without ZooKeeper) the controller inside Kafka now manages this process directly. This means simpler operations and the same goal: fair load, minimal disruption and steady throughput.
Trade-offs to Keep in Mind
- More partitions – better scalability and parallelism
- Too many partitions – higher metadata overhead, slower recovery
- Key-based partitioning – ensures ordering for a key
- Global ordering across partitions is not guaranteed
Key Takeaway
Partitioning is what gives Kafka its scalability and flexibility. The right partitioning strategy depends on your usecase
- if you need strict ordering – use a key
- if you need high throughput – increase partitions
- if you need both – design carefully to balance between ordering and scalability
To summarize. In your projects, always start by asking what you need to guarantee – ordering, throughput, or load balancing – and design your partitioning strategy accordingly.
I encourage you to read also my other posts about architecture.